Serverless client-side telemetry aggregation
Published on Saturday, July 20, 2019In this blog post, I’m going to walk through a serverless approach to collecting and analyzing telemetry from web applications. This tutorial uses the AWS ecosystem, specifically CloudFront, Lambda, Kinesis Firehose, S3, Glue, and Athena.
Motivation
If you’re looking for an alternative to Google Analytics, many options have fixed costs. Open-source solutions like Piwik may require running persistent infrastructure, and SaaS solutions may have high subscription fees. The approach outlined in this post relies exclusively on metered services, some with free tiers. Additionally, when running a system like the one described in this post, you retain ultimate control of all data collected. You can collect and keep as much or as little data as you would like, and the design can be altered to accommodate different data types that may not be compatible with third-party services.
I’m rolling my own analytics because I’d like to know how long viewers spend on each page of this site, and I don’t want to either:
- Pay a fixed monthly fee for this service when this blog has few readers, or
- Expose viewers to unnecessary tracking.
By using serverless telemetry, I can limit the amount of data gathered and only pay when the site actually gets read.
System overview
At a high level, the telemetry system consists of three parts:
- JavaScript that captures events in the Elastic Common Schema and submits them as JSON to a beacon endpoint, and
- Backend services that host that beacon endpoint, convert the data received into an optimized format, and store it in S3.
- AWS Athena, which will let us query the ingested data using SQL without any persistent infrastructure.
Client-side telemetry submission
The client-side code for this system is fairly simple. For a time-on-page
metric, we’ll just listen for the unload
event and use it to send a message toour beacon endpoint:
<html>
<head>
<script>
window.addEventListener("unload", function () {
navigator.sendBeacon(
"https://cloudfront.distribution.url",
JSON.stringify({
'@timestamp': (new Date()).toISOString(),
'event.action': 'pageview',
'event.duration': performance.now() * 1000000,
'http.request.referrer' document.referrer,
})
);
});
</script>
...
We’ll go over the beacon URL in the next section, but that’s all the client-side code we need! We’re not using tracking cookies or storing any data on the user’s device; you can add that if you need to tie events to specific users, but I don’t want cookie notices or GDPR headaches for my blog.
The above snippet relies on two web APIs:
navigator.sendBeacon- Enqueues small payloads for asynchronous delivery. Browsers have
traditionally ignored HTTP requests sent from
unloadevent handlers because the window will have been closed by the time a response is received, so browser vendors introducednavigator.sendBeaconfor sending requests when you do not need to handle the response. Not supported in Internet Explorer.
- Enqueues small payloads for asynchronous delivery. Browsers have
traditionally ignored HTTP requests sent from
performance.now- A monotonic clock that reports how many milliseconds have elapsed since the
host
windowobject was created.
- A monotonic clock that reports how many milliseconds have elapsed since the
host
The Elastic Common Schema is very rich, so you can capture as much or as little data as you need. You can use the same endpoint and processing infrastructure to, for example, capture client side logs by sending messages such as:
{
"@timestamp": <timestamp>,
"message": "An error occurred!",
"log.level": "error",
"error.code": "NETWORKING_ERROR",
"error.message": "<url> could not be reached"
}
The Parquet-based backend does not support the schema’s nested object syntax, so
make sure you use the flattened syntax instead. (I.e.,
{"error.code": "ERROR_CODE", "error.message": "error message"} instead of
{"error": {"code": "ERROR_CODE", "message": "error message"}}).
Serverless beacon and data ingestion
We’ll use a few AWS services to stand up our beacon and ingestion system:
- CloudFront will host the beacon URL,
- Lambda@Edge will process incoming requests,
- Kinesis Firehose will batch incoming events and convert them from JSON into a more efficient format,
- S3 will store received data,
- Glue will store metadata, and
- Athena will execute queries against the data stored in S3.
All of these services use metered billing, which means we’ll only get billed when the infrastructure is actually used. If no one reads this blog and no events are sent to the beacon URL, then this system will cost $0.00 to run.
Overall, the system will look like this:
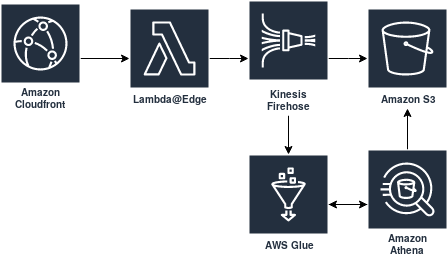
Requests will be sent to CloudFront, which will invoke a Lambda@Edge function for each request. This lambda function will add some server-side data to the received telemetry (such as the IP address of the client), then send the event to a Kinesis Firehose delivery stream. Firehose will use a projection of the Elastic Common Schema that we have stored in Glue to convert records from JSON into Apache Parquet, which both reduces the size of records stored and allows efficient querying of single columns. The parquet files are then stored in S3.
Beacon endpoint
Our beacon endpoint consists of a CloudFront distribution that invokes a lambda function for each request received. In CloudFormation terminology, we need to create a Lambda function, tag a version of that function, and associate said version to a CloudFront distribution:
# Telemetry events will be ingested through a CloudFront distribution
ClientSideTelemetryIngester:
Type: AWS::CloudFront::Distribution
Properties:
DistributionConfig:
Enabled: True
HttpVersion: http2
DefaultCacheBehavior:
AllowedMethods:
- GET
- HEAD
- OPTIONS
- PUT
- PATCH
- POST
- DELETE
ForwardedValues:
QueryString: False
TargetOriginId: EffOrigin
ViewerProtocolPolicy: redirect-to-https
# Here's where we tell CloudFront to just invoke our Lambda for every
# request
LambdaFunctionAssociations:
- EventType: viewer-request
LambdaFunctionARN:
Ref: ClientSideTelemetryLambdaFunction.Version
# CloudFront requires that we specify an origin, even though we won't be
# sending any requests to it (they are all handled by the lambda
# function).
Origins:
- DomainName: www.eff.org
Id: EffOrigin
CustomOriginConfig:
OriginProtocolPolicy: https-only
# This will be the lambda function that ingests individual messages
ClientSideTelemetryLambdaFunction:
Type: AWS::Serverless::Function
Properties:
Handler: 'index.handler'
Runtime: 'nodejs8.10'
MemorySize: 128
Role:
Fn::GetAtt:
- ClientSideTelemetryLambdaRole
- Arn
Timeout: 5
AutoPublishAlias: live
InlineCode:
Fn::Sub: |
'use strict';
const Firehose = require('aws-sdk/clients/firehose');
exports.handler = (event, context, callback) => {
const request = event.Records[0].cf.request;
if (request.method === 'POST' && request.body && request.body.data) {
const ecsEvent = JSON.parse(Buffer.from(request.body.data, 'base64').toString());
if (ecsEvent['@timestamp'] === undefined) {
ecsEvent['@timestamp'] = (new Date).toISOString();
}
ecsEvent['client.ip'] = request.clientIp;
const {headers = {}} = request;
if (ecsEvent['url.full'] === undefined && headers['referer']) {
ecsEvent['url.full'] = headers['referer'][0].value
}
if (headers['user-agent']) {
ecsEvent['user_agent.original'] = request.headers['user-agent'][0].value;
}
const fh = new Firehose({region: "${AWS::Region}"});
const req = {
DeliveryStreamName: "${ClientSideTelemetryDeliveryStream}",
Record: {
Data: JSON.stringify(ecsEvent)
}
};
fh.putRecord(req, (err, resp) => {
if (err) {
callback(err);
} else {
callback(null, {status: '200'});
}
});
} else {
callback(null, {status: '415'});
}
};
Lambda@Edge differs from standard Lambda in a few ways. It has a different
pricing model, only functions written in Node are supported, and you have to
associate a specific function version ARN with a distribution (a function ARN on
its own won’t work). I couldn’t get Lambda’s promised-based handler to work with
Lambda@Edge and had to use a handler that takes a callback, but otherwise the
lambda handler itself should look familiar if you’re used to using lambdas with
other event sources. Using the AWS::Serverless::Function resource
type
will take care of tagging and publishing versions of the lambda function.
One thing to note: when writing the CloudFormation template in July 2019, I was unable to have CloudFront forward the request body to the associated Lambda function without logging into the AWS console. After deploying the template, you will need to:
- Visit the distribution in the CloudFront console,
- Navigate to the
Behaviorstable, - Select the default behavior,
- Click the
Editbutton, - Scroll down to the
Lambda Function Associationssection, - Click the
Include Bodycheckbox, and then - Click the
Yes, Editbutton.
This will trigger another deployment of the CloudFront distribution, which may take up to fifteen minutes. I’ll update this post in the future if CloudFront adds support for controlling this feature via CloudFormation.
Firehose ingestion
The main action taken by the lambda function described above is to submit events to a Kinesis Firehose delivery stream. This AWS resource will receive up to 5,000 records per second, buffer them until a certain size or time limit is reached, optionally pass the buffered records through a lambda function and/or data format converter, and then deliver the batch of records to a configured destination for storage. We’ll be using S3, but you can also configure Firehose to deliver to Redshift, Splunk, or Elasticsearch. Firehose charges a few cents per gigabyte of data received, and you don’t have to provision any persistent infrastructure.
Because our beacon endpoint is stateless and ephemeral, we’ll be relying on
Firehose to buffer telemetry into larger files and then convert those files into
Apache Parquet. Parquet is a columnar data format
with built-in compression, so parquet files are often an order of magnitude
smaller than the equivalent data stored in JSON. Because each column is stored
separately, queries in Athena for a subset of columns (e.g., SELECT ts, message from ecs_events) don’t need to scan data that hasn’t been requested and are
therefore much cheaper to run.
Firehose can perform the conversion to Parquet automatically for a couple cents per gigabyte using a schema describing the data it receives. This schema must be stored in AWS Glue using the Hive data definition language:
# This is where our telemetry data will be stored
ClientSideTelemetryBucket:
Type: AWS::S3::Bucket
# The next two resources establish a schema for telemetry events
ClientSideTelemetryDatabase:
Type: AWS::Glue::Database
Properties:
# CatalogId must always be the AWS Account ID in which the database is
# provisioned
CatalogId:
Ref: AWS::AccountId
DatabaseInput:
Description: "Aggregated client-side telemetry"
Name: client_side_telemetry
ClientSideEcsTelemetryTable:
Type: AWS::Glue::Table
Properties:
CatalogId:
Ref: AWS::AccountId
DatabaseName:
Ref: ClientSideTelemetryDatabase
TableInput:
Description: "Aggregated client-side Elastic Common Schema events"
Name: ecs_events
# This property tells Glue our data is stored outside of Glue (i.e., S3)
TableType: EXTERNAL_TABLE
Parameters:
classification: parquet
# Partition keys are present in the S3 path rather than in the file itself
# They will allow Athena to limit the number of files it has to read to
# execute a query when one or more partition keys is specified.
PartitionKeys:
-
Type: int
Name: year
-
Type: int
Name: month
-
Type: int
Name: day
-
Type: int
Name: hour
StorageDescriptor:
Location:
Fn::Sub: "s3://${ClientSideTelemetryBucket}/data/ecs/"
StoredAsSubDirectories: True
SerdeInfo:
SerializationLibrary: 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
InputFormat: 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OutputFormat: 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
# This property describes the contents of the files stored in S3
Columns:
# Omitted for brevity here, but available in the complete template
ClientSideTelemetryDeliveryStream:
Type: AWS::KinesisFirehose::DeliveryStream
Properties:
DeliveryStreamType: DirectPut
ExtendedS3DestinationConfiguration:
BucketARN:
Fn::GetAtt:
- ClientSideTelemetryBucket
- Arn
RoleARN:
Fn::GetAtt:
- ClientSideTelemetryDeliveryStreamRole
- Arn
# The next two properties tell Firehose where to write batched data
Prefix: "data/ecs/year=!{timestamp:yyyy}/month=!{timestamp:MM}/day=!{timestamp:dd}/hour=!{timestamp:HH}/"
ErrorOutputPrefix: "errors/ecs/!{firehose:error-output-type}/year=!{timestamp:yyyy}/month=!{timestamp:MM}/day=!{timestamp:dd}/hour=!{timestamp:HH}/"
# Parquet queries are more efficient with larger files, so we'll instruct
# Firehose to batch data for 15 minutes or until 128 MBs are waiting to be
# processed.
BufferingHints:
IntervalInSeconds: 900
SizeInMBs: 128
# Snappy compression is intrinsic to the parquet format, so disable any
# further compression.
CompressionFormat: UNCOMPRESSED
# This property tells Firehose that we'll be sending JSON and want it
# converted to parquet
DataFormatConversionConfiguration:
Enabled: True
InputFormatConfiguration:
Deserializer:
OpenXJsonSerDe:
# Glue column names may only contain lowercase letters and
# underscores, so the following properties will convert an ECS
# record into something compatible with Glue.
# For example,
# {"@timestamp":"2019-07-14T00:00:00Z","log.level":"error"}
# would become
# {"ts":"2019-07-14T00:00:00Z","log_level":"error"}
ColumnToJsonKeyMappings:
ts: "@timestamp"
ConvertDotsInJsonKeysToUnderscores: True
OutputFormatConfiguration:
Serializer:
ParquetSerDe: {}
SchemaConfiguration:
CatalogId:
Ref: AWS::AccountId
DatabaseName:
Ref: ClientSideTelemetryDatabase
Region:
Ref: AWS::Region
TableName:
Ref: ClientSideEcsTelemetryTable
VersionId: LATEST
RoleARN:
Fn::GetAtt:
- ClientSideTelemetrySchemaReaderRole
- Arn
Complete CloudFormation template
A complete CloudFormation template for this stack can be viewed here. Please note that after launching the stack, you will need to visit the CloudFront console and edit the behavior associated with the lambda function. There is an “Include Body” checkbox that cannot be controlled via CloudFormation; until it is checked, the request body will not be passed to the lambda function.
Querying
AWS Athena will automatically allow you to query data whose schema is stored in Glue. If you deployed the CloudFormation template for the system, you should be able to visit the Athena console and issue queries with no further setup required.
Please note that you may need to load partitions before querying what’s stored in S3. Because the collected telemetry is time series data, new partitions will be routinely added.
A more serverful alternative: Elasticsearch
Kinesis Firehose can be configured to deliver records to an Amazon Elasticsearch Service cluster instead of S3, which may integrate better with your existing systems and workflows. If you want to adapt the system described above to use Elasticsearch, remove the Glue and S3 resources from the CloudFormation template and update the Firehose delivery stream configuration to use an Elasticsearch Service destination.
No changes would be required of the client-side code.